
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 계몽의변증법
- 뒤르켐
- 취업준비생연구
- 고급통계
- 세종시
- 동시출현의미망
- Grouped-BarChart
- 베이지안통계학
- 청년비경제활동인구
- 고급통계학
- HLM
- 청년연구
- LDA분석
- 광기의역사
- 사회학
- 데이팅앱
- 행렬
- 통계학분포
- AHP분석
- LDA
- 아도르노
- 육체의 변증법
- 베버
- 독립표본t검정
- 취준연구
- 파슨스
- 공동생산
- 논술대회
- 데이터분석
- Topicmodeling
- Today
- Total
Look, See, Why
토픽 모델링이란? 토픽 모델링의 원리/가정/차원/알고리즘 본문
• 대규모 텍스트 데이터에서 숨겨진 '주제(Topic)'나 '이슈'를 추출하는 분석 방법
• 문서마다 반복적으로 등장하는 단어들의 동시 사용 패턴(빈도와 함께 등장)을 계산하여 데이터 전체에 포함된 N개의 주제를 찾아내는 것이 목표
• 머신러닝의 비지도 학습(unsupervised learning) 방식 중 하나로, 주제를 사전 정의하지 않고 찾아내는 방식임.
->지도학습은 정답이 있는 데이터를 학습 입력 데이터와 함께 각 입력에 대응하는 정답을 미리 알려주고 모델을 학습시킴.
(ex.게임에서 욕설을 입력했을 때 자동으로 처리해주는 것. / 감정 분석.
->비지도학습은 라벨이 없는 데이터만으로 동작 정답값 없이, 숨겨진 패턴이나 데이터의 그룹을 스스로 찾아내는 방식.
방향성이 없음. 빅데이터를 탐색하고 분석하기에 적합하다.
[원리]
• 여러 문서 내 특정 단어들의 등장 확률을 바탕으로 자주 함께 등장하는 단어 집합을 하나의 주제인 '토픽'으로 간주한다
• 각 문서는 N개의 토픽이 특정 확률로 혼합되어 있다는 가정에서 출발함,
• 문서-토픽 분포 : 문서 내에 어떤 토픽이 얼마나 포함되어 있는가?
• 토픽-단어 분포 : 토픽 내에 어떤 단어가 얼마나 대표적인가?
[토픽 모델링 가정]
• 각 토픽은 단어들의 분포이다.
• 각 문서는 여러 토픽들의 분포이다.
• 각 단어는 각 토픽으로부터 가져온다.
[차원축소]
• 차원의 저주 : 고차원 벡터(문서-단어 행렬)은 너무 많은 연산량과 저장 공간을 요구함.
• 과적합문제 : 학습데이터에 포함된 노이즈까지 너무 자세히 학습하게 되어 새로운 데이터에 대해 잘 일반화하지 못함.
(-->토픽의 개수가 너무 많아진다.)
• 차원 축소 : 유의미하지 않은 단어들을 제거해서 효과적으로 분석해볼 수 있음.
불용어를 제거하고, 유의어를 지정(처리)해본다. (내 주제에 맞춰서 설정을 하면 됨)
전체 문서의 몇 % 이상 등장하는 단어거나 너무 적게 등장하는 단어는 제거하는 식으로.
• 3개의 파라미터
1) 토픽수
2) α(문서별 토픽 분포 파라미터) : α가 클수록 한 문서는 여러 주제를 포함하며 작을수록 소수 주제에 집중
3) β(토픽별 단어 분포 파라미터) : β가 크면 한 토픽이 다양한 단어로 구성되고,작으면 특정 몇 단어로만 구성
• 재현성 : LDA는 확률 기반 토픽 모델이기 때문에, 학습 과정에서 무작위성이 개입한다.
재현성을 위해서 3개의 파라미터, 랜덤 시드, 학습 횟수는 고정(명시)해야 한다.(투고할 때) <-처음에 코드를 짤 때 아예 요청을 하자.
[사용 라이브러리]
-gensim, scikit-learn, tomotopy
[토픽 모델링 알고리즘]
• LDA : 잠재 디리클레 할당 (대표)
ㄴBlei가 처음 만들었다. 문서는 여러 가지 잠재 주제들의 확률적인 조합으로 생성된다는 발상을 베이지안 확률 모델로 구현하였으며, 기존 텍스트 분석 모델들의 고질적인 과적합 문제를 해결하고 뛰어난 일반화 성능을 달성했다는 데 의의가 있음.
• DTM (Dynamic Topic Modeling)
• DMR (Dirichlet Multinomial Regression)
• STM (Structural Topic Modeling) (파이썬에는 없고 R에 있다)
[토픽수(K) 계산]
-Perplexity(혼란도) : 모델이 문서의 단어를 예측할 때, 얼마나 많은 선택지에 놓이는지 보여주는 지표
낮을수록 유리
-Coherence(응집도) : 각 토픽 안에 속한 단어들이 의미적으로 얼마나 서로 잘 어울리는지를 보여 주는 지표
높을수록 유리
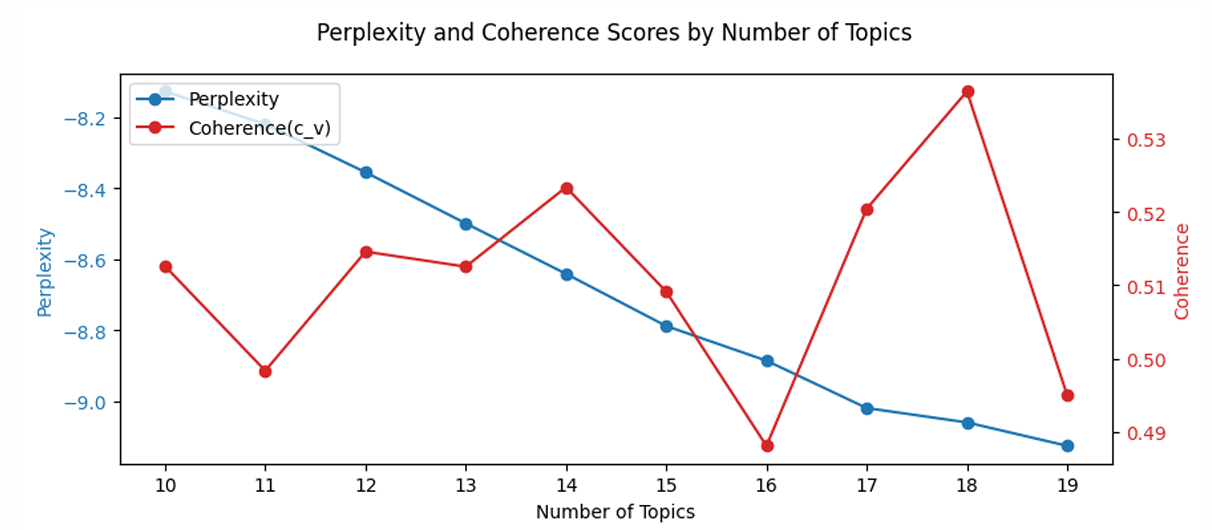
하지만 합의가 없기 때문에.. 연구자의 역량에 따라서. 토픽을 얼마나 잘 설명하느냐에 따라 정하면 됨.
'사회학 공부 > 통계 및 데이터분석' 카테고리의 다른 글
| 패널고정효과모형과 잠재계층성장분석 (0) | 2026.04.13 |
|---|---|
| [기초통계] 가설검정/독립표본t검정 (0) | 2026.04.09 |
| [기초통계] t 검정 (차이검정) (0) | 2026.04.01 |
| [기초통계] 표본분포와 추정 (0) | 2026.04.01 |
| 고급통계란 무엇인가? 그리고 고급통계의 종류 (0) | 2026.03.31 |


