
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 데이팅앱
- 데이터분석
- 논술대회
- 세종시
- 아도르노
- HLM
- Grouped-BarChart
- 파슨스
- LDA
- LDA분석
- 베버
- 취업준비생연구
- 베이지안통계학
- AHP분석
- 육체의 변증법
- 청년비경제활동인구
- 뒤르켐
- 공동생산
- 사회학
- 동시출현의미망
- 고급통계
- 통계학분포
- 계몽의변증법
- 행렬
- Topicmodeling
- 청년연구
- 고급통계학
- 취준연구
- 독립표본t검정
- 광기의역사
- Today
- Total
Look, See, Why
Propensity Score Matching(성향점수매칭, PSM) 분석 본문
-nnmatching과 PSM은 selection이다. 데이터를 다 갖고와서 쓰지 않고 선택해서 사용한다는 의미.
●기본 개념
-성향점수(Propensity Score) : 관찰된 공변량(독립변수들)이 주어졌을 때 해당 개체(개인)마다 처치를 받을 조건부 확률
-> 성향 점수를 어떻게 만들 것인지가 제일 중요.
-통상 Logit 모델을 통해 산출하지만 probit도 가능하다.
-PSM의 기본원리 : 성향점수를 산출하고, 점수가 같은(최대한 비슷한) 대상을 선택하여 평균적 차이를 분석한다.

실험집단과 통제집단으로 나누더라도 사람마다 받을 확률들이 다르다. ex. 의료정책을 시행한다고 하자. 저연령, 고연령, 비수혜, 수혜라고 했을 때 사람마다 정책 수혜를 받을 확률이 다르다.


개인마다 실험집단에 들어갈 확률, 통제집단에 들어갈 확률

● nnmatch 옵션 활용
-nneighbor(2) -> 성향 점수가 가장 가까운 군 하나 + 그다음 가까운 하나

(비교대상을 어떻게 할 것인가? 나랑 최대한 가까운 군까지, 그 다음 군까지?를 정하는게 중요함)
●caliper 옵션
-STATA에서는 성향 점수의 차이가 아무리 크더라도, 상대 그룹에서 그나마 점수가 제일 비슷한 사람을 찾아 무조건(억지로) 매칭하기 때문에 비교의 타당성이 떨어질 수 있음. 이러한 편향을 방지하기 위해 caliper 옵션을 사용한다.
-caliper의 숫자를 높이면 많은 사람이 매칭되고, 숫자를 줄이면 적은 사람이 매칭된다.

->caliper 값은? 편향을 효과적으로 줄이기 위해서 표준편차의 0.2배를 제안 (Rosenbaum&Rubin, 1985)
->teffects psmatch (bweight) (mbsmoke mmarried c.mage##c.mage fbaby medu), caliper(0.2)
-nneighbor을 너무 줄여도, 너무 늘려도 안된다. 너무 작으면 선택편향이 생기며, 숫자가 너무 크면 결과값이 커진다.
-Robust 검정 : nneighbor을 몇 개까지 할 것인가? 1,2,3까지는 괜찮다가 (4)까지 갔더니 결과가 갑자기 큰 변화가 생기면 (3)까지 해도 되는 것이다. (1)로 너무 적게하면 선택편향이 생길 수 있다.
●Quietly 옵션이란?
-Rubin(2008)은 연구자가 처치 효과의 추정치를 확인하고 나면 결과를 위해 모형을 조작하고 싶은 유혹에 빠질 수 있다. 따라서 처치 효과를 확인하기 전에 성향 점수 모형 등을 통해 공변량이 처치군과 대조군 사이에서 균형을 이루는지 먼저 검증해야 한다고 권고한다.
->quietly 옵션을 사용해라!
quietly: teffects ipw (bweight) (mbsmoke mmarried mage prenatal1 fbaby)
: 처리는 되었으나 결과는 안뜸. 유의한 결과값을 보면 마음이 흔들린다. 따라서 사후검정을 해라.
●공변량의 Balance 확인
-공변량 균형 조건 : 처치군과 대조군의 공변량 분포가 같아야 (비슷해야) 분석할 수 있음.
그렇지 않으면 Overidentifying(과잉식별)이 된다. 과잉식별 = 변수에 쓸 데 없는 게 들어갔다.
과잉식별 확인 : tebalance overid
-first moment : 평균
-second moment : 분산, 표준편차
-성향 점수 모형이 완벽하게 명시되었다면, 이 모형을 통해 '가중치를 적용했을 때 모든 공변량의 moment가 처치 여부와 상관없이 0이 되어야 한다'는 조건이 성립 -> 카이제곱 검정(귀무가설 : "공변량이 균형을 이룬다") -> 귀무가설이 기각되면 overidentifying
●tebalance summarize, baseline
:밸런스가 깨진 것을 확인하는 코드

평균 차이가 0에 가까울 수록, 분산 비율이 1에 가까울 수록 밸런스.
-tebalance density mage : treatment level별로 mage로 인한 불균형 정도를 확인하기 위한 명령어
●matching 이후의 balance 확인
-tebalance density mage
->과식별 확인 후 분포 확인 가능하다

-tebalance box

->box plot으로도 확인 가능하다
순서 : 모델 돌리기 -> 과식별확인 -> 균형 깨졌다면 summarize / 그림 둘 중 하나로 확인한다 (summarize 추천)
●Overlap assumption 성립여부 확인 (★)
-Overlap이 되어있지 않다면 비교하는 것 자체가 의미가 없어진다. 기본 가정임.
-teoverlap
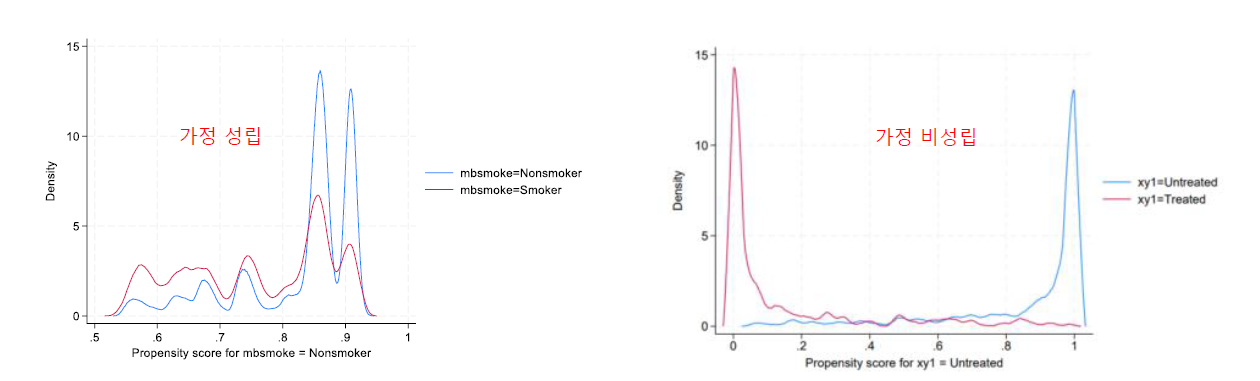
-teffects psmatch (bweight) mbsmoke mmarried mage prenatal1 fbaby),osample nmatch
-teffects psmatch (bweight) mbsmoke mmarried mage prenatal1 fbaby) if nmatch ==0
--> overlap assumption 가정이 위배될 경우 nmatch==0인 것을 찾아서 제외시킬 수 있다.
'사회학 공부 > 통계 및 데이터분석' 카테고리의 다른 글
| 생존분석의 이해 -> 세종시 청년 전입전출 아이디어 (0) | 2026.01.03 |
|---|---|
| Difference-in-Differences estimation (DID) / 패널데이터 분석 / HDID(코호트) (0) | 2025.12.03 |
| AHP 데이터 분석 실습 - Gender Data를 이용함 (0) | 2025.11.23 |
| 행렬과 Nearest-Neighbor matching(NNM) (0) | 2025.11.19 |
| Inverse-Probability Weighting(IPW) 를 이용한 Treatment Effect 추정 (0) | 2025.11.17 |

